




Institute for Telecommunication Sciences / About ITS / 2025 / NR Audio Estimator Training with Independent Datasets
ITS Open Source Software Advances Training No-reference (NR) Speech Quality Estimators with Independent Datasets
To make the most efficient use of available bandwidth, how much can speech and video be compressed before the end user perceives them as degraded? ITS’s Audio Quality and Video Quality research programs have been addressing this question for decades, providing answers that have advanced innovation in communications technologies to enable innovative and efficient uses of America’s wireless airwaves.
Recently, Audio Quality delivered yet another innovative breakthrough, a neural network called AlignNet [1]. AlignNet was developed in response to a fundamental stumbling block in the way of developing in-service speech quality estimators. AlignNet efficiently and effectively removes misalignments among diverse machine learning training data sets that impair the learning process, and thus enables successful training with larger amounts of more diverse data.
The Audio Quality research team at ITS has extensive experience in signal processing and subjective listening experiments. In recent years, it has also been working and making contributions to machine learning (ML) no-reference (NR) speech quality estimators [2–5]. The team’s background and interests in signal processing motivate researchers to focus their efforts on developing interpretable ML solutions.
Algorithms that, for any recording, estimate speech quality and other speech and audio attributes without access to a clean reference signal are called no-reference (NR) algorithms or estimators. NR estimators are highly desirable because they allow operators to adjust network parameters continuously and in real time to maintain the optimal bandwidth. However, NR estimators have proven very hard to develop, much harder than estimating through comparison to the original reference signal (called full-reference estimation).
Originally, full-reference algorithms were primarily designed using signal processing principles to emulate human hearing and judgement. As ML matured and became widely accessible, NR estimators became more feasible and quickly improved. To be successful, an ML-based NR estimator requires a lot of labeled data for training.
For speech quality algorithms, labels mean subjective speech quality scores collected from people in subjective listening experiments. Subjective experiments are costly and challenging to run—labeled speech data is a valuable resource! During the Covid pandemic, when laboratory subjective experiments were not possible multiple labs began generously sharing crowd-sourced subject experiment data, so that work on developing ML-based NR estimators could continue.
Individual datasets can be used to train an ML algorithm, and the more data an ML algorithm is exposed to during training, the more accurate is its performance on unseen data. However, there is a known problem trying to merge multiple, independent datasets to build a larger body of labeled speech data: Datasets from different sources are often incompatible.
Researchers know that a key reason independent listening experiments are typically not compatible with each other is because of a phenomenon called “the corpus effect”. In any given experiment, the quality score a listener assigns to an audio excerpt is not absolute; it depends on the other audio excerpts heard in the experiment — including the range of qualities, the types of impairments, and other components — as well as additional acoustical and non-acoustical biases unique to each. This means that the exact same audio clip could get significantly different quality scores in different experiments.
When training an ML NR estimator, the corpus effect makes it challenging to simultaneously leverage multiple datasets, because standard algorithms cannot make use of incompatible labels. A unique architecture is needed to enable learning how to reconcile incompatible labels and benefit from them.
Enter AlignNet.
In the paper “AlignNet: Learning dataset score alignment functions to enable better training of speech quality estimators,” presented at Interspeech 2024, co-authors Jaden Pieper and Stephen D. Voran report on how they developed and evaluated a novel ML architecture to address the problem of the corpus effect. They call this neural network AlignNet.
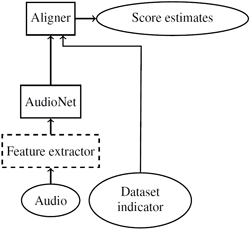
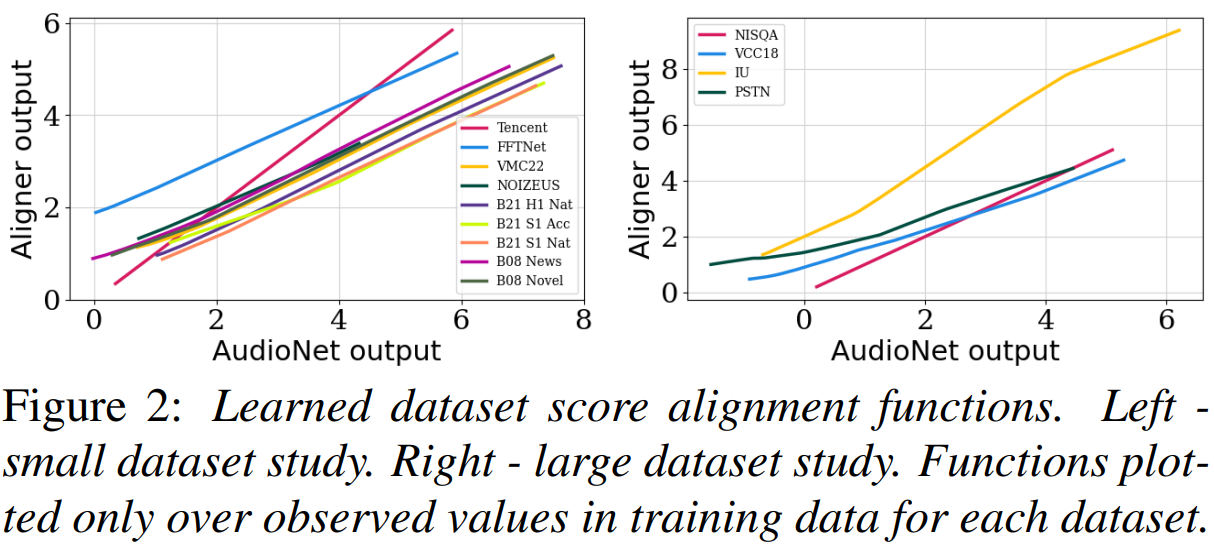
optional depending on the choice of AudioNet.
Technically speaking, AlignNet uses an AudioNet to generate intermediate score estimates before using the Aligner to map intermediate estimates to the appropriate score range. Pieper and Voran intentionally designed AlignNet to be agnostic to the choice of AudioNet, so any successful NR speech quality estimator can benefit from its Aligner.
AlignNet outperforms other known approaches to training with multiple datasets. The ITS experiment used an unprecedented 13 datasets covering 3 languages, scores for 4 different speech attributes, and a very wide range of measurement domains, totaling over 300 hours of speech.
Further, the results of the Aligner are very interpretable and can offer valuable insights into the relationships of different listening experiments. Interpretable ML solutions are essential to building confidence and trust, and they open the door for future research developments and improvements.
ITS will continue its work in developing models, tools, and software that accurately characterize the user experience of speech communications technology. This will involve further exploration of the impacts and improvements afforded by dataset alignment. ITS will also work to improve the accuracy of speech quality estimators and improve the interpretability of those models and their results.
[1] J. Pieper and S. Voran “AlignNet: Learning dataset score alignment functions to enable better training of speech quality estimators,” Proc. Interspeech 2024, 2024, pp. 82–86, doi: 10.21437/Interspeech.2024-74.
[2] A. A. Catellier and S. D. Voran, “WAWEnets: A No-Reference Convolutional Waveform-Based Approach to Estimating Narrowband and Wideband Speech Quality,” IEEE International Conference on Acoustics, Speech and Signal Processing, 2020, pp. 331–335, doi: 10.1109/ICASSP40776.2020.9054204.
[3] S. Voran, “Measuring Speech Quality of System Input while Observing only System Output,” IEEE International Conference on Quality of Multimedia Experience, 2021, pp.125–128, doi: 10.1109/QoMEX51781.2021.9465448.
[4] S. Voran, “Full-Reference and No-Reference Objective Evaluation of Deep Neural Network Speech,” IEEE International Conference on Quality of Multimedia Experience, 2021, pp. 85–90, doi: 10.1109/QoMEX51781.2021.9465433.
[5] A. A. Catellier and S. D. Voran, “Wideband Audio Waveform Evaluation Networks: Efficient, Accurate Estimation of Speech Qualities,” IEEE Access, vol. 11, pp. 125576–125592, 2023, doi: 10.1109/ACCESS.2023.3330640.